정확히 말하면, 흩어져 있는 데이터를 수직하여, 그 데이터를 각각의 종류 별로 모으고(Map), Filtering과
Sorting을 거쳐, 각각의 개수를 뽑아내는(Reduce) 분산처리 기술과 관련 프레임워크를 의미합니다.
이 때 단순히 개수만이 아니라 추가적인 연산 작업으로 더 다양한 의미있는 분석 결과를 뽑을 수 있습니다.
Map은 흩어져 잇는 데이터를 Key, Value의 형태로 연관성 있는 데이터 분류로 묶는 작업,
Reduce는 Map화한 작업 중 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업입니다.
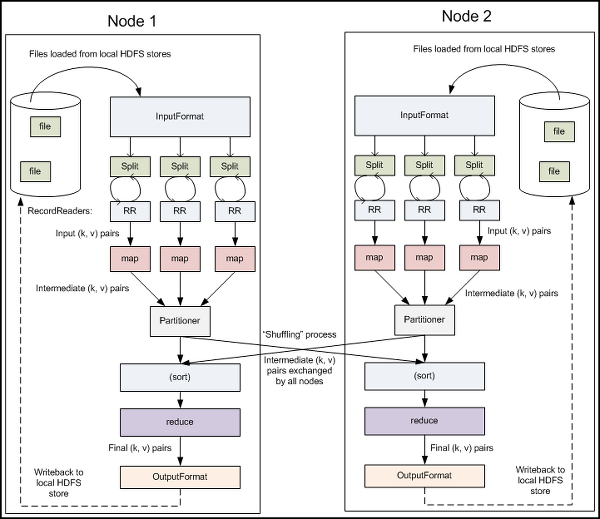
① MapReduce로의 Input
Input File
<!--[if !supportLists]-->- <!--[endif]-->HDFS에 저장되어 있는 파일들을 불러와서 Map Reduce를 진행합니다
Input Format
<!--[if !supportLists]-->- <!--[endif]--> HDFS에 저장되어 있는 Input file을 한 줄씩 불러와서 맵 리듀스를 진행하게 됩니다.
|
Input Splits
<!--[if !supportLists]-->- <!--[endif]--> 하나의 파일을 정해진 파일 처리 단위로 나누어 줍니다. Input Format이 'TextInputFormat'이거나 'KeyValueInputFormat'인 경우에는 한 줄 씩 나누어주는 역할을 합니다.
RecordReader(RR)
<!--[if !supportLists]-->- <!--[endif]--> 나누어진 파일 처리 단위를 Input Format에 따라 (Key,Valeu)의 형식으로 정형화 하여 줍니다. 이런 형식으로 데이터를 구성한 뒤에 Map() 메소드를 지속적으로 불러와서 실행시키게 됩니다.
② Mapper
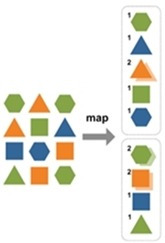
위의 그림처럼, 입력 받은 데이터를 분석하여 새로운 Key와 Value 값을 갖는 형태로 구성한 뒤, OutputCollector라는 객체에 담아서 반환하게 됩니다. Record Reader로부터 데이터를 한 줄씩 입력 받게 되고, 한 줄의 데이터를 입력받아 하나 또는 여러 개의 (Key, Value) 결과값을 생성하게 되는 것입니다. 이 때, 입력받은 하나의 (Key, Value) 데이터에 대해서 Map 과정을 수행하고 결과값을 생성하기 때문에 분산되어 있는 데이터를 옮기지 않고 저장 되어 있는 Node에서 바로 처리가 가능합니다. 그리고 입력받은 하나의 (Key, Value) 데이터만으로 결과값을 생성하므로 다른 데이터와 연관된 정보는 Map과정에서는 얻을 수 없습니다.
③ Partition& Shuffle, Sort
Map 과정이 끝나고 나온 결과 데이터는 여러 개의 노드에 무질서하게 존재 하게 됩니다. 이 결과 데이터들을 Key에 따라 나누어서 Reduce 메소드를 진행하게 될 Node로 보내게 되는데 이 과정을 Shuffling이라고 합니다. 그리고 Map 의 결과로서 나오게된 중간 (Key, Value) 세트를 Partition이라고 합니다.
정해진 키 값을 가진 데이터들이 Reduce 메소드가 진행 될 slave node로 옮겨진 뒤, Reduce는 같은 Key값을 같은 데이터를 모아서 처리하게 되는데 이를 위해서는 sort과정이 필요하게 됩니다. sort까지 마친 데이터들이 Reduce로 넘어가서 진행되게 되는 것입니다.
④ Combiner
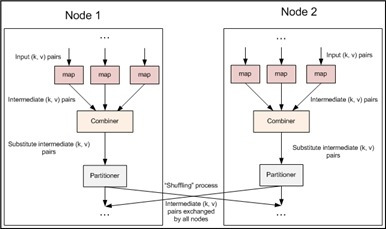
Combiner는 Mapreduce 파이프라인에서 Map과 Partitioner 사이에 존재합니다. Combiner는 꼭 필요한 기능은 아니지만 적절히 사용하면 성능 향상에 큰 도움이 될 수 있습니다. Combiner는 map에서 나온 결과 데이터를 Reduce와 같은 방식으로 같은 Key를 갖는 데이터들을 입력받아 원하는 결과를 만들어 낼 수 있습니다. Reduce와의 차이점은 한 Node에서 일어난 map의 결과에 대해서만 실행되기 때문에, Combine 만으로는 원하는 결과를 얻을 수 없다는 점입니다. 하지만 분산되어 처리되는 Combiner는 Reduce의 계산량을 많이 줄여 줄 수 있습니다.
⑤ Reducer
|
|
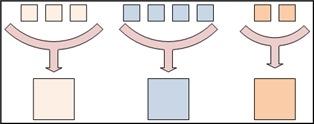
Redeuce는 Key값이 같은 모든 정보들을 Input으로 갖습니다. 같은 Key값을 같는 모든 데이터를 리스트의 형태로 입력 받은 뒤 이들의 조합에서 원하는 결과를 분석할 수 있습니다. 또한 Output 데이터는 한 개 또는 여러개의 (Key, Value)형식 또는 다양한 형식으로 만들어 낼 수 있습니다.
⑥ MapReduce로부터의 Output
OutputFormat
- OutputCollector 객체에 담겨져 있는 데이터들을 정해준 형식에 따라 미리 정해준 경로에 파일 형식으로 저장하게 됩니다. Output파일 형식은 다음 표와 같이 3가지 형식이 있습니다.
|
TextOutputFormat 형식으로 결과 파일을 생성할 경우에 TextInputFormat으로 연속으로 다음 Map-Reduce과정을 실행 할 수 있다는 장점이 있습니다.
자, 이제 Map-Reduce의 실질적으로 Hadoop에서 어떻게 동작하는지 알아보도록 하겠습니다.
그 속의 과정을 이해하셔야 Map-Reduce를 효과적으로 사용할 수 있습니다.
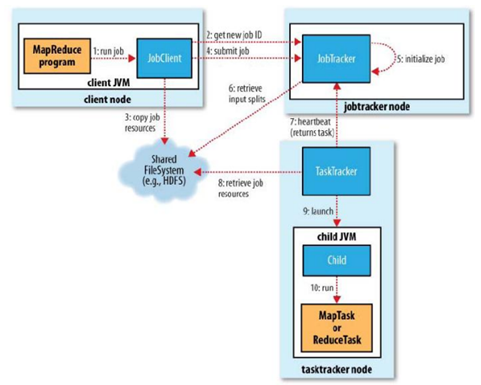
<!--[endif]-->
위의 그림은 Hadoop에서 Map-Reduce를 진행하는 과정입니다.
하나씩 과정을 살펴보면 다음과 같습니다.
<!--[if !supportLists]-->1) <!--[endif]-->맵리듀스 프로그램에 의해 실행된 작업은 JobClient의 runJob() 메소드에 의해 새로운 JobClient 인스턴스를 생성하고 submitJob() 메소드를 호출합니다.
<!--[if !supportLists]-->2) <!--[endif]-->submitJob()메소드 그림의 2,3,4과정을 진행합니다. 즉 잡트래커에 새로운 잡ID를 요청(getNewJobId() 메소드 호출)합니다. 잡의 명세를 확인하고 잡에 대한 입력 스플릿들을 계산합니다. 잡 수행에 필요한 자원들인 잡 JAR 파일, 설정파일, 입력 스플릿 정보들을, 해당 잡ID를 이름으로 하는 디렉터리에 복사합니다. 마지막으로 잡트래커가 잡을 시작할 준비가 되었음을 알립니다.
<!--[if !supportLists]-->3) <!--[endif]-->잡 초기화단계(5단계)에서는 잡을 큐에 넣고, 잡 스케쥴러는 그것을 가져가서 초기화합니다. 또한 수행할 태스크 목록을 생성하기 위해, 잡 스케줄러는 3단계에서 저장된 입력 스플릿들을 가져오게 됩니다.(6단계)
<!--[if !supportLists]-->4) <!--[endif]-->그리고 태스크트래커는 heartbeat를 주기적으로 호출하여 잡트래커에 보내는 단순 루프를 수행합니다. 잡에는 우선순위가 존재하며, 이는 스케줄링 알고리즘에 의해서 수행되게 됩니다. (여기서 스케줄링 알고리즘은 다양하게 존재합니다)
<!--[if !supportLists]-->5) <!--[endif]-->이어서 태스크트래커노드에서 JVM을 실행하고, 각 잡이 이 JVM에서 수행하게 됩니다.
간단히 설명했지만, 사실 좀 더 복잡한 흐름을 갖게 됩니다. 일단 기본적인 흐름을 숙지하신 후에, Hadoop
Document 혹은 책을 통해서 자세히 이해하시길 바랍니다.
'DB' 카테고리의 다른 글
| multiple row to single row (0) | 2017.02.06 |
|---|---|
| HDFS (0) | 2014.11.28 |
| NOSQL (0) | 2014.11.28 |
| ORACLE 쿼리 분석(실행계획) (0) | 2014.11.28 |
| ORACLE HINT (0) | 2014.11.28 |